
I’ve been listening to the Hacker News daily podcast made by 面条. He open-sourced the code, so I wanted to build a podcast about autism, ADHD and neurodiversity, and reuse the same approach.
But these useful resources are usually spread across websites and newsletters. They are not centralized like the Hacker News website. So I modified the original project to reading newsletter content, then use AI to summarize and analyze it, and finally generate a podcast.
The workflow is actually simple: read subscribed newsletters → summarize → generate a podcast script → generate audio/text -> publish.
Interestingly, the original project uses Cloudflare Workflow, which can be almost zero-cost to deploy. But this setup also caused a few problems for me. I’m writing them down here.
The output is open sourced herrkaefer/any-podcast
Newsletter sources
At first, I created a new Gmail account, subscribed to related newsletters, and labeled them accordingly. Then I enabled the Gmail API, so the program could read emails in a time range and process the content.
But after a few days, Google marked the account as abnormal and banned it (it was restored after an appeal though). That made this approach feel unreliable and I would not try it with my personal Gmail account. Also, parsing email content is annoying.
Later I found a great free tool: kill-the-newsletter. You subscribe to newsletters using the email address it provides, and it automatically converts newsletters into RSS. This makes reading the content much easier.
Content-agnostic, configuration-driven
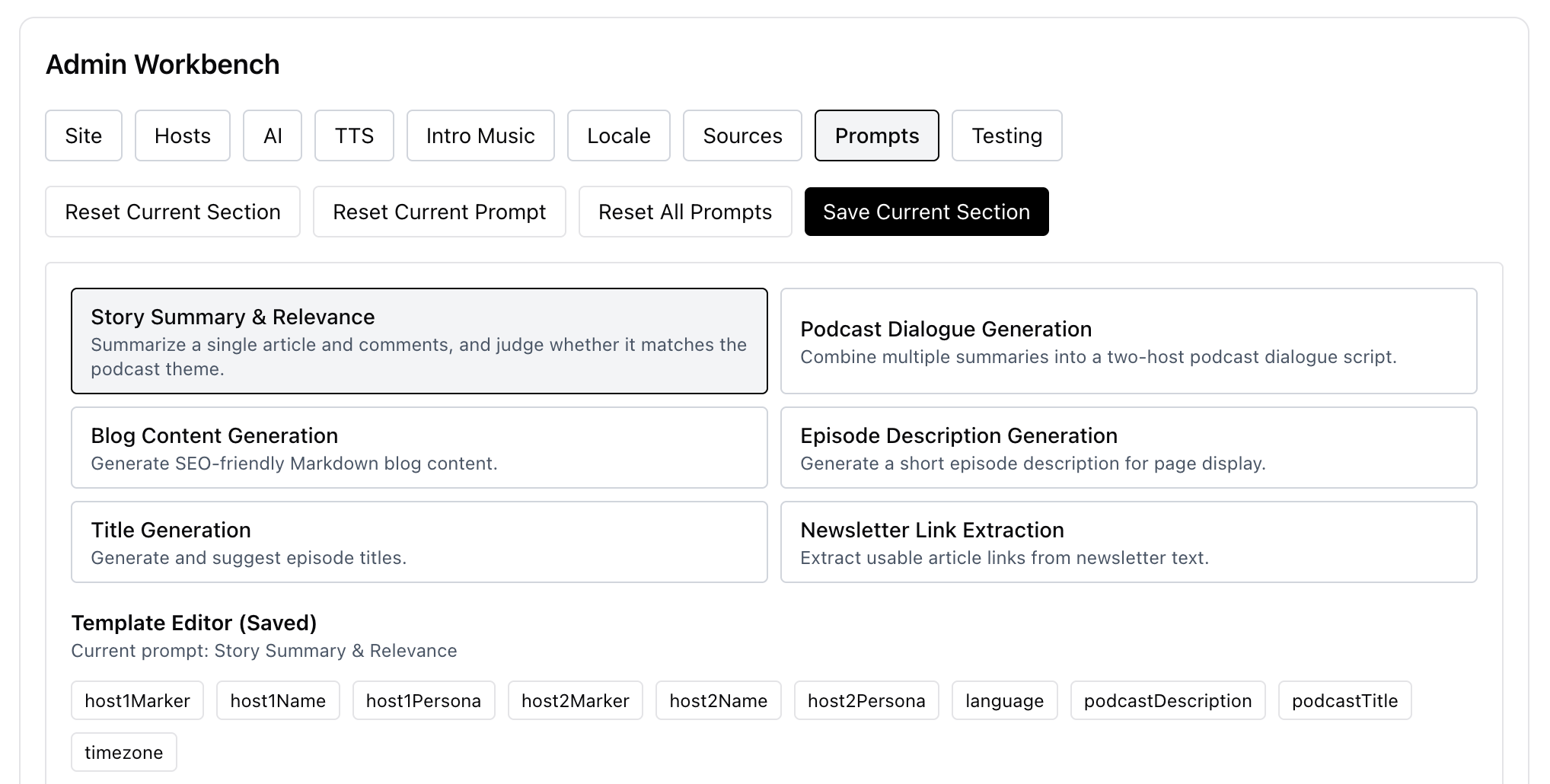
My goal was to make the podcast generator not depend on any specific content source, and instead be fully driven by configuration. So I added an admin page to configure each step: content sources, images, prompts, and so on.
TTS consistency: batching sounds easy, but fails in practice
I tried Gemini TTS in batch mode (generate audio in segments and then stitch them together). I wanted to reduce failures when generating long audio in one go. But the voice consistency was poor: the tone and style slightly drifted between segments, and the final result sounded like “multiple hosts”.
So if you use Gemini, it’s better to generate the audio from the full text in one shot.
Gemini also supports multi-speaker voices built in, which is very convenient.
If you use Minimax TTS to generate sentence by sentence and then merge, the voice does not drift at all, and the Chinese voice quality is much better.
Workflow limits (subrequests): instead of “saving requests”, just “continue in a new run”
Cloudflare Worker’s subrequest limit bothered me for a while: on the free plan, each run can only make up to 50 subrequests, which is easy to exceed. To avoid hitting the limit, I had to manually limit how many articles I read, which is not ideal.
Later I tried a “multiple workflows relay” approach, and it worked well.
What I do:
- Estimate subrequest usage inside the workflow (it seems you can only estimate it)
- When it’s close to the limit (for example, 40), create and trigger a new workflow to continue
The new workflow is basically a new instance of the same workflow. For the handoff, I write the current state into KV, and the next workflow reads the state and continues.
With this method, in theory I no longer need to worry about how many newsletters there are.
Podcasts
 |  |
Hope you enjoy listening.